
트랜잭션의 개념을 여러분들은 많이 들어보셨을 것이다.
트랜잭션
작업을 처리하는 명령의 모임.
이 작업은 모두 성공하거나, 중간에 하나라도 실패하면 이전 성공도 모두 실패로 돌아간다는 원자성을 가진다.
즉 실패하면 롤백.
트랜잭션의 개념을 이해한 채로 스프링 프로젝트를 진행하면서 CUD가 있는 코드에는 @Transactional을 거의 로봇처럼 붙여주며 진행했다.
그런데 이 트랜잭셔널 어노테이션이 트랜잭션을 보장해준다고는 하지만 내부가 어떻게 동작하는지에 대해서는 모르는 사람이 되게 많다.
나 또한 몰랐었고, 이번에 정리를 통해 천천히 개념을 집어보려고 한다.
간단한 테스트를 통해 트랜잭션이 어떻게 되는지 알아보자.
@Getter
@NoArgsConstructor
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private String email;
@Column(nullable = false)
private int age;4개의 정보를 가지는 User를 만들어서 회원가입 메서드, 전체 조회 메서드를 만들었다.
저장 메서드
// 유저 저장
@Override
public UserResponseDTO save(UserDTO userDTO) {
User user = UserDTO.toEntity(userDTO);
User savedUser = userRepository.save(user);
UserResponseDTO userResponseDTO = UserResponseDTO.toDTO(savedUser);
return userResponseDTO;
}따로 트랜잭션은 걸지 않고 UserDTO를 입력으로 받아 User Entity로 변환 -> 저장 후 User를 UserResponseDTO로 변환하여 리턴
조회 메서드
// 모든 유저 조회
@Override
public List<UserResponseDTO> findAll() {
List<User> userList = userRepository.findAll();
List<UserResponseDTO> responseDTOS = userList.stream()
.map(UserResponseDTO::toDTO)
.toList();
return responseDTOS;
}찾아온 List<User>를 Stream을 이용해서 UserResponseDTO의 List로 변경

저장도 정상적으로 동작되고

데이터도 잘 찾아오도록 구현했다.
근데 내가 지금 구현한 로직에는 어떤 문제가 있을까?
지금 save의 문제는 트랜잭션을 걸어두지 않은 것이 문제다.
만약에 save를 해서 DB에 저장까지 시켰는데 예외가 발생한다면 어떻게 될까?
// 유저 저장
@Override
public UserResponseDTO save(UserDTO userDTO) {
User user = UserDTO.toEntity(userDTO);
User savedUser = userRepository.save(user);
UserResponseDTO userResponseDTO = UserResponseDTO.toDTO(savedUser);
throw new RuntimeException("유저 저장 중 예외 발생");
}만약 위 코드처럼 save를 시킨 이후 리턴하려고 할 때 예외가 발생했다면?
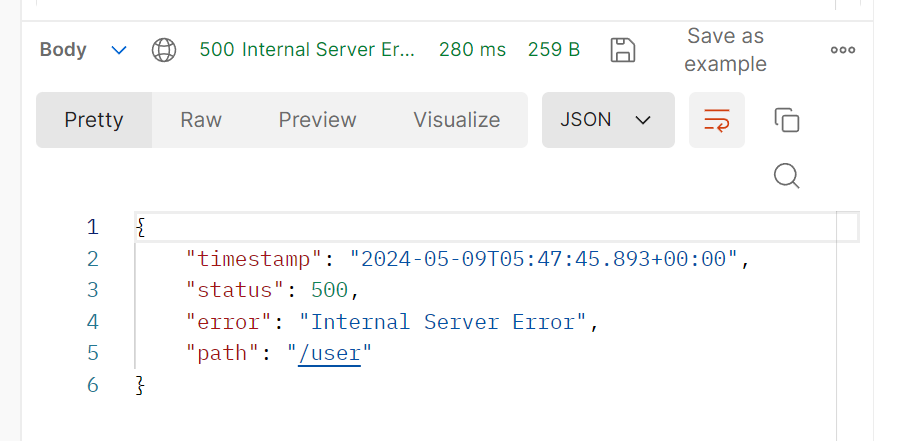
500과 함께 런타임 에러가 발생했으며, 저장 메서드에 문제가 생겼지만?

방금 가입시킨 유저의 정보가 DB에 반영된 것을 볼 수 있다.
즉 트랜잭션을 걸지 않아서 중간에 실패했지만 실패 이전까지 성공했던 내역이 그대로 반영된 것.
트랜잭션을 걸게 되면
1. 유저 회원가입 시도. (데이터 저장)
2. 에러 발생
3. 유저 회원가입 롤백.
이 과정을 통해 원자성을 보장해주게 된다.
// 유저 저장
@Override
@Transactional
public UserResponseDTO save(UserDTO userDTO) {
User user = UserDTO.toEntity(userDTO);
User savedUser = userRepository.save(user);
UserResponseDTO userResponseDTO = UserResponseDTO.toDTO(savedUser);
throw new RuntimeException("유저 저장 중 예외 발생");
}이렇게 @Transactional 어노테이션을 붙이고 실행시켜 주면
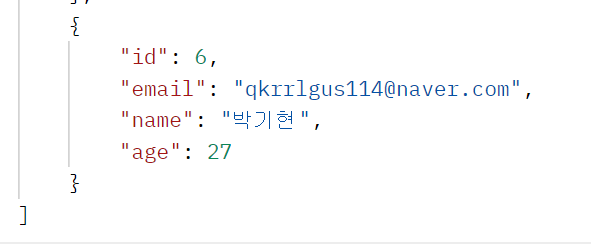
실패해도 7번 유저가 DB에 저장되지 않고 롤백되는 것을 확인할 수 있다.
그럼 저 어노테이션이 대체 어떤 구조로 돌아가길래 이런 기능을 가능하게 해줄까?
정답은 스프링 AOP와 프록시에 있다.
AOP는 관점지향 프로그래밍으로 프록시 객체를 통해 추가적인 작업을 진행 후 실제 로직을 호출하도록 만드는 프로그래밍 중 하나이다. (즉 관심사를 분리시킨다.)
그럼 관심사가 무엇일까?
우리가 매번 작성하는 서비스 로직에는 비즈니스 로직이 존재한다.
즉 어떤 기능을 수행하기 위한 핵심 로직들인데, CUD의 경우 트랜잭션 보장이 거의 필수적인데 이런 트랜잭션 보장을 서비스 내에서 전부 해준다면??
메서드1(){
트랜잭션 시작();
서비스();
트랜잭션 커밋();
}
메서드2(){
트랜잭션 시작();
서비스();
트랜잭션 커밋();
}
메서드3(){
트랜잭션 시작();
서비스();
트랜잭션 커밋();
}
....
매 서비스마다 중복되는 로직들이 들어가게 되고 개발자는 비즈니스 로직에 집중하는 것이 아니라, 그 외적인 트랜잭션 로직도 계속 신경 써야 한다는 문제가 발생한다.
그래서 @Transactional 어노테이션은 트랜잭션 기능을 분리시켜 공통으로 수행하도록 만들고, 개발자는 비즈니스 로직에만 집중할 수 있도록 AOP를 통해 구현해 놓은 어노테이션이다.
@Transactional
해당 어노테이션을 붙여놓은 클래스는 프록시 객체로 만들어지게 된다. 여기서 프록시 객체는 대리자를 의미하는데, 만약에 회원가입 메서드를 호출하면 바로 UserService의 회원가입을 호출하는 것이 아니라
(UserService프록시 -> 트랜잭션 시작 -> UserService 회원가입 호출) 이 과정으로 이루어지게 된다.
즉 실제 서비스를 호출하는 대리자의 역할을 수행하는 것.

기존에는 위와 같은 관계를 가지게 된다. UserController에서 UserSerivce로 향하는 관계
그러나 Proxy가 추가되면

UserController는 Proxy 객체를 호출하게 되고, Proxy 객체에서 실제 UserService를 호출하게 되는 것.
즉 @Transactional 어노테이션을 붙이게 되면 UserServiceProxy라는 것이 생성되는 것이다.
그러면 UserController에서 주입받는 UserSerivce의 참조값이 뭔가 변경점이 생기지 않을까?
@Transactional을 적용하지 않을 경우 (Proxy 없음)

일반적인 UserService의 참조값이 주입되어 있다.
@Transactional을 적용했을 경우 (Proxy 있음)

CGLIB을 통해 만들어진 Proxy 클래스가 주입된 것을 알 수 있다.
Proxy를 만드는 방법에 대해 JDK와 CGLIB이 존재하는데 해당 내용은 다른 블로그에 많이 소개되어 있다.
즉 트랜잭션을 적용시키면 UserService에 프록시 객체가 생성되어 주입되게 되는 것.
1. 회원가입 호출
2. UserService 프록시 객체로 접근
3. 트랜잭션 시작
4. UserService의 회원가입 메서드 시작
5. 완료되면 커밋 or 롤백 실행
이 순서를 통해 원자성을 보장하게 해주는 것.
@Transactional(readonly = true)
위 어노테이션은 많은 사람들이 Read만 실행하는 메서드에서 붙여놓은 것을 확인할 수 있다. 이것의 장점은 다음과 같다.
1. 더티체킹을 수행하지 않는다.
기존에는 JPA에서 조회하는 Entity를 스냅샷으로 만들어두고 영속성 컨텍스트에서 변경사항을 추적해서 Update 쿼리를 생성시켰다.
그러나 readonly를 걸어두면 더티체킹을 진행하지 않아서 값이 수정되어도 DB에 자동으로 반영되지 않는다.
2. 스냅샷을 생성하지 않는다.
기존에는 Entity를 조회하면 초기 스냅샷을 찍어두었는데, readOnly를 걸어두면 스냅샷을 찍지 않아서 리소스 절약이 된다.
3. flush 모드를 매뉴얼로 변경한다.

HibernateJpaDialect 구현체는 다음과 같은 메서드를 통해 readOnly 값을 읽어와서 true면 FlushMode를 매뉴얼로 변경시킨다.

즉 flush를 명시적으로 호출할 때만 플러시를 진행시키기에 자동으로 데이터를 반영시키는 문제를 막아주게 된다.
결국 @Transactional(readonly = true)를 굳이 사용하지 않아도 문제는 없지만, 읽기만 하는 경우 예상치 못한 데이터의 변경을 막아줄 수 있다는 장점을 가지게 된다.
참조
https://studyandwrite.tistory.com/573
Spring READ 관련 API에서 @Transactional(readOnly = true)는 필수인가?
Spring에서는 @Transactional(readOnly = true) 옵션을 제공합니다. 실제로 많은 사람들이 쓴 글들을 보면 조회 관련 API에서 @Transactional(readOnly = true) 옵션을 사용하면 성능 상 이점을 얻을 수 있다고 말하는
studyandwrite.tistory.com
https://docs.jboss.org/hibernate/core/3.6/reference/en-US/html/readonly.html
Chapter 12. Read-only entities
Important Hibernate's treatment of read-only entities may differ from what you may have encountered elsewhere. Incorrect usage may cause unexpected results. In some ways, Hibernate treats read-only entities the same as entities that are not read-only: Even
docs.jboss.org
@QueryHint의 readOnly 와 @Transaction의 readOnly 차이 - 인프런
안녕하세요. @QueryHint 의 readOnly 속성과 관련하여 질문있습니다. 이전의 강의(jpa 활용 1편) 에서 service 단에 @Transaction(readOnly=true) 설정을 주었을 때 영속성 context flush (X), dirty checki...
www.inflearn.com
'CS지식' 카테고리의 다른 글
| HTTP 응답(상태) 코드에 대한 정리 (0) | 2024.05.16 |
|---|---|
| Tomcat은 정확히 어떤 역할을 하는 도구일까? (0) | 2024.05.12 |
| Interceptor와 Filter는 뭐가 다를까? (0) | 2024.05.06 |
| 스프링 IOC와 DI를 어떻게 설명해야 할까? (0) | 2024.05.05 |