
현재 서비스에서 사용하는 모든 쿼리를 분석하고 다음의 내용을 개선해보려고 한다.
1. 불필요한 정보 조회 -> DTO 조회로 변경
2. N+1 문제 확인하기
3. 인덱스 타는지 파악하기(쿼리 실행 계획)
아래는 쿼리 개선을 진행하며 남긴 기록들이다.
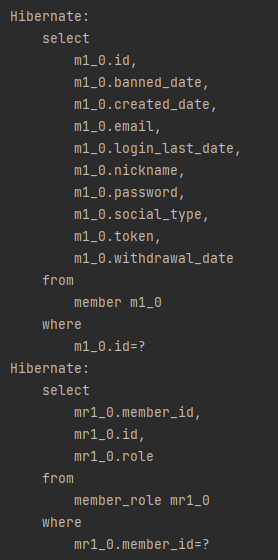
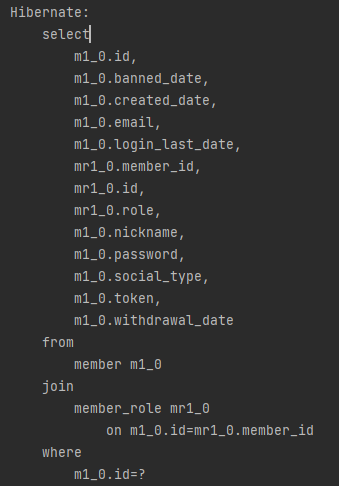
메인화면 유저 정보 가져오기
fetchJoin을 걸어두지 않아서 Role를 가져올 때 따로 조회를 진행한다.
따로 MemberRoles와 fetchJoin을 통해 N+1 문제를 해결. (왼쪽 기존, 오른쪽 개선)
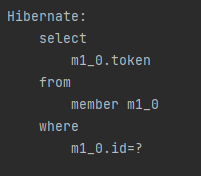
유저의 토큰 조회
토큰의 개수만 필요한데 유저의 전체 데이터를 가져오는 것은 낭비라고 판단. 토큰만 파악할 수 있도록 변경했다.
id에 일치하는 데이터가 없을 수도 있기 때문에 Optional로 감싸주었다.
// 토큰 개수 반환
@Query("select m.token from Member m where m.id = :id")
Optional<Integer> findByMemberToken(@Param("id") Long id);
왼쪽 쿼리에서 오른쪽으로 변경 완료.
데일리 쿠폰 조회
아래의 쿼리를 통해 쿠폰을 하나 찾아오게 만들어 두었다.

해당 쿼리의 실행계획을 보면 INDEX를 타지 않는 것으로 확인했다.

해당 데이터는 매일 하나씩 생기기 때문에 하루가 지날 때마다 데이터가 늘어난다. 그래서 인덱스 조회를 하는 게 낫다고 판단.
따로 날짜에 대한 인덱스를 생성해주었고 인덱스를 활용하도록 변경했다.

유저의 쿠폰 획득
유저가 쿠폰을 획득할 때 6개의 쿼리가 나가는 것을 확인.
1. 유저 조회
2. 쿠폰 획득 기록 조회
3. 오늘 쿠폰 데이터 조회
4. 쿠폰 기록 생성
5. 유저 쿠폰 데이터 업데이트
6. 남은 쿠폰 데이터 업데이트
여기서 주목했던 부분은 2번이다. 2번에는 수많은 유저들의 쿠폰 기록이 남아있다.
이 데이터에서 해당 유저가 오늘 쿠폰을 획득했는지를 판단하게 된다.
문제는 해당 쿼리가 인덱스를 타지 않고 있던 것.

조회 조건은 (날짜 and 유저) 이렇게 2개를 이용한다. 그래서 날짜와 유저를 같이 복합 인덱스로 만들어줬다.

특정 게시글 가져오기
공유 게시판에서 특정 게시글을 눌렀을 때 나가는 쿼리는 아래와 같다.
왼쪽은 게시글을 보여주기 위한 데이터, 오른쪽은 현재 유저가 좋아요를 눌렀는지 여부이다.
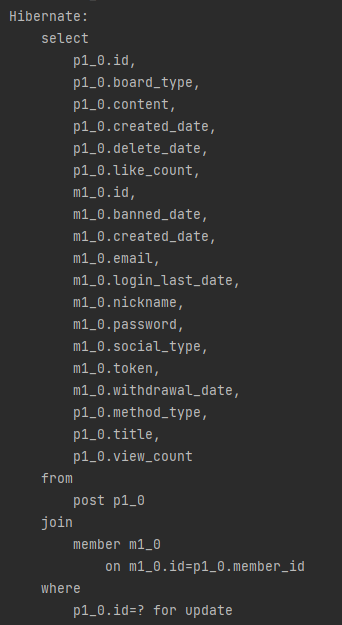
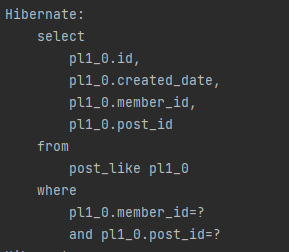
화면에 보여주는 데이터에 비해 왼쪽에 SELECT 하는 데이터가 너무 많다고 판단.
실제로는 7개의 데이터만 사용하는데 19개의 데이터를 조회하고 있다. 얘를 DTO 조회로 변경.
기존 쿼리
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select p from Post p join fetch p.member where p.id = :id")
Optional<Post> findByIdWriteLockFetchJoinMember(@Param("id") Long id);
개선 쿼리
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select new com.park.restapi.domain.board.dto.response.TargetPostInfo(" +
"p.id, m.nickname, p.title, p.content, p.createdDate, p.likeCount, p.viewCount) " +
"from Post p left join p.member m where p.id = :id")
Optional<TargetPostInfo> findByIdWriteLockFetchJoinMemberDTO(@Param("id") Long id);
19개의 select에서 7개로 줄은 것을 확인할 수 있다.
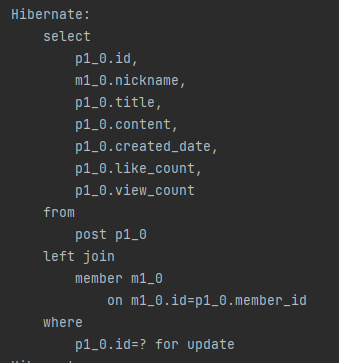
DTO를 하나 만들어서 조회하면서 발생한 문제가 조회수 업데이트 문제.
Entity를 가져오는 게 아니어서 더티체킹도 불가능했다. 그래서 그냥 update 쿼리를 하나 만들었다.
(어차피 기존에도 변경하면 update 쿼리 날리니 동일하다 판단.)
@Modifying
@Transactional
@Query("update Post p set p.viewCount = p.viewCount + 1 where p.id = :id")
void findByIdUpdateViewCount(@Param("id") Long id);update를 진행하기에 @Modifying을 걸어주었고 DB를 변경하기에 트랜잭셔널을 같이 사용한다.
API 요청 이력 조회
아래는 현재 쿼리의 상태다.
// 모든 api 요청 내역 조회
@Override
public Page<ApiRequestHistoryResponseDTO> searchApiRequestHistory(Pageable pageable) {
List<ApiRequestHistoryResponseDTO> results = queryFactory.select(
Projections.constructor(ApiRequestHistoryResponseDTO.class, apiRequestHistory.member.id,
apiRequestHistory.requestDate, member.email, apiRequestHistory.methodType,
apiRequestHistory.requestContent, apiRequestHistory.responseContent))
.from(apiRequestHistory)
.leftJoin(apiRequestHistory.member, member)
.orderBy(apiRequestHistory.requestDate.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
long total = queryFactory.select(apiRequestHistory.count())
.from(apiRequestHistory)
.fetchOne();
return new PageImpl<>(results, pageable, total);
}
100만 개 데이터 기준으로 90000번째 페이지를 검색했을 때(count 제외)
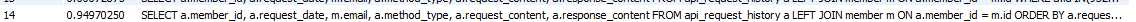

0.9 초의 시간이 걸린다.
여기에도 이전에 적용했던 deferred join과 커버링 인덱스를 통해 성능 향상을 시도해보려고 한다.
deferred join 적용
List<Long> apiRequestsIds = queryFactory.select(apiRequestHistory.id)
.from(apiRequestHistory)
.orderBy(apiRequestHistory.requestDate.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
List<ApiRequestHistoryResponseDTO> results = queryFactory.select(
Projections.constructor(ApiRequestHistoryResponseDTO.class, apiRequestHistory.member.id,
apiRequestHistory.requestDate, member.email, apiRequestHistory.methodType,
apiRequestHistory.requestContent, apiRequestHistory.responseContent))
.from(apiRequestHistory)
.leftJoin(apiRequestHistory.member, member)
.where(apiRequestHistory.id.in(apiRequestsIds))
.orderBy(apiRequestHistory.requestDate.desc())
.fetch();
long total = queryFactory.select(apiRequestHistory.count())
.from(apiRequestHistory)
.fetchOne();기존 쿼리를 2개로 구분시켰다.
1. offset 90000, limit 10 기준으로 해당하는 기록의 id만 조회
2. 10개의 id에 대해서만 dto로 조회를 진행.
기존에는 모든 데이터를 돌고 조인하면서 버린다음에 10개를 찾았지만 이제는 id만 10개를 찾고 10개만 데이터를 조회하기 때문에 불필요한 조회가 크게 줄어든다.
2개의 쿼리를 동일하게 offset 90000, limit 10으로 조회를 진행하면

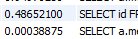
두 쿼리가 합쳐서 0.5초가 되지 않는다.
즉 deferred join을 통해 0.9 -> 0.5로 절반 가까이 조회 시간을 줄일 수 있었다.
더 성능을 줄이기 위해 인덱스를 확인해보자.
List<Long> apiRequestsIds = queryFactory.select(apiRequestHistory.id)
.from(apiRequestHistory)
.orderBy(apiRequestHistory.requestDate.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
안타깝게도 INDEX를 타지 않는다. filesort를 사용하는 것을 확인.
날짜 기준으로 정렬을 진행하고 있어서 날짜에 인덱스를 걸어주었다.
인덱스를 사용하도록 변경 완료

2번째 쿼리는 10개의 데이터만 가져오기에 굳이 인덱스를 타지 않아도 된다고 판단했다.
그 결과 두 개 합쳐서 0.03초로 성능을 개선할 수 있었다.

0.9초 -> 0.03초로 성능을 약 30배 개선했다.
'프로젝트 > RESTAPI 추천 서비스' 카테고리의 다른 글
| 도커 허브를 추가하여 이미지 백업을 구성하기. (0) | 2024.06.23 |
|---|---|
| 배포를 위해 진행했던 도커와 젠킨스 정리 (0) | 2024.06.21 |
| certbot SSL 인증서 갱신하기 (1) | 2024.06.11 |
| 서비스에서 남겨지는 log를 slack으로 보내보자. (0) | 2024.06.09 |