
만약에 String 값을 int로 변환해야 한다면 뭘 선택할 건가?
대부분 알고리즘을 풀다 보면 parseInt를 쓰는 사람, valueOf를 쓰는 사람 둘로 나뉜다.
그래서 차이점을 찾아보면 공통적으로 하는 말들이 parseInt는 int로 반환하고, valueOf는 Integer로 반환해서 null을 받을 수 있다. 이게 끝이다.
내부적으로 동작하는 캐싱에 대한 이야기는 들어있는 글이 별로 없었다. 나도 예전에 Long값을 변환하면서 valueOf를 사용하다가 문제를 마주쳤던 경험이 있었기에 내부 로직을 파보려고 한다.
Integer.parseInt
아래 코드는 가장 많이 작성하는 문자열 -> 정수 변환 코드다.
int i = Integer.parseInt("123");
내부적으로 먼저 한 단계 들어가면 radix라는 인자를 같이 전달해주고 있다.
radix : 기수를 의미한다. (10진수, 2진수, 16진수 등, 여기서 10을 전달하니 10진수를 의미한다.)

밑의 코드가 들어온 문자열을 정수로 변환해주는 로직이다.
negative를 false로 두고, -가 붙었다면 true로 변경한다. 이후 문자 하나씩 보면서 계산한 값을 result에 담아서 리턴해준다.
이때 리턴 타입은 int로 기본 타입이다.
boolean negative = false;
int i = 0, len = s.length();
int limit = -Integer.MAX_VALUE;
if (len > 0) {
char firstChar = s.charAt(0);
if (firstChar < '0') { // Possible leading "+" or "-"
if (firstChar == '-') {
negative = true;
limit = Integer.MIN_VALUE;
} else if (firstChar != '+') {
throw NumberFormatException.forInputString(s, radix);
}
if (len == 1) { // Cannot have lone "+" or "-"
throw NumberFormatException.forInputString(s, radix);
}
i++;
}
int multmin = limit / radix;
int result = 0;
while (i < len) {
// Accumulating negatively avoids surprises near MAX_VALUE
int digit = Character.digit(s.charAt(i++), radix);
if (digit < 0 || result < multmin) {
throw NumberFormatException.forInputString(s, radix);
}
result *= radix;
if (result < limit + digit) {
throw NumberFormatException.forInputString(s, radix);
}
result -= digit;
}
return negative ? result : -result;
} else {
throw NumberFormatException.forInputString(s, radix);
}
가끔 숫자 변환을 하다보면 NumberFormatException이 발생하곤 한다.
- 첫 번째 인수가 null 이거나 길이가 0인 문자열인 경우.
- 기수는 가 2보다 작거나, 36보다 큰 경우.
- 문자열의 모든 문자가 지정된 기수의 숫자가 아닌 경우.
- 문자열로 표현된 값은 int 유형의 값이 아닌 경우.
위 조건을 하나라도 만족하지 않으면 NumberFormatException이 발생하게 된다.
Integer.valueOf
아래 코드처럼 정수로 변경할 수 있다. 반환값은 Integer로 해주기에 int로도 받을 수 있다.(오토 언박싱)
int i = Integer.valueOf("123");
내부 코드는 parseInt와 동일하게 radix를 넘긴다. 그런데 주목할 부분은 parseInt를 한 값을 valueOf로 넘긴다는 것이다.

내부 valueOf로 들어가면 아래와 같은 코드로 작성되어 있다.
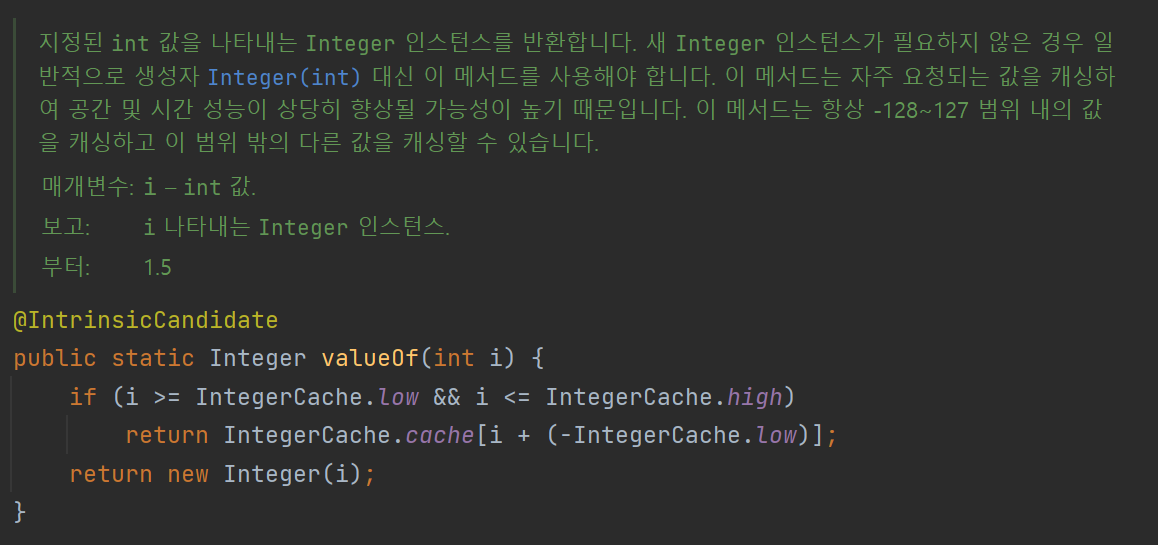
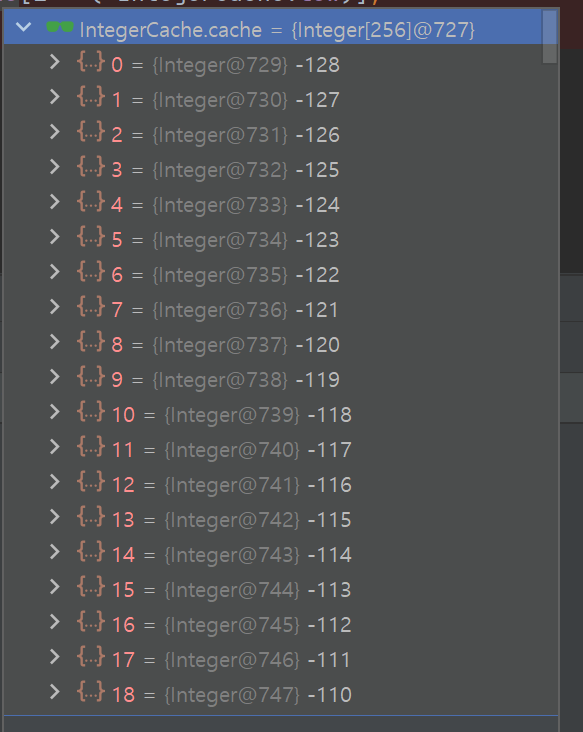
여기서 흥미로운 점은 IntegerCache를 사용한다는 건데 해당 cache는 배열로 이루어져 있다. -128 ~ 127의 값을 미리 캐싱해 놓는다.
이게 사실 parseInt와 valueOf의 가장 큰 차이점이 않을까 싶다.
우선 파라미터로 들어오는 int i에는 이미 parseInt로 변환한 int 값이 들어오게 되어 있다. 이후 i의 값이 -128 ~ 127 범위에 속하는지 먼저 판단을 진행한다.
아래 코드에 해당 캐시 이너클래스가 존재한다. cache 배열을 만들어두고 여기에 데이터를 캐싱해 놓고 진행하는 것으로 추측.
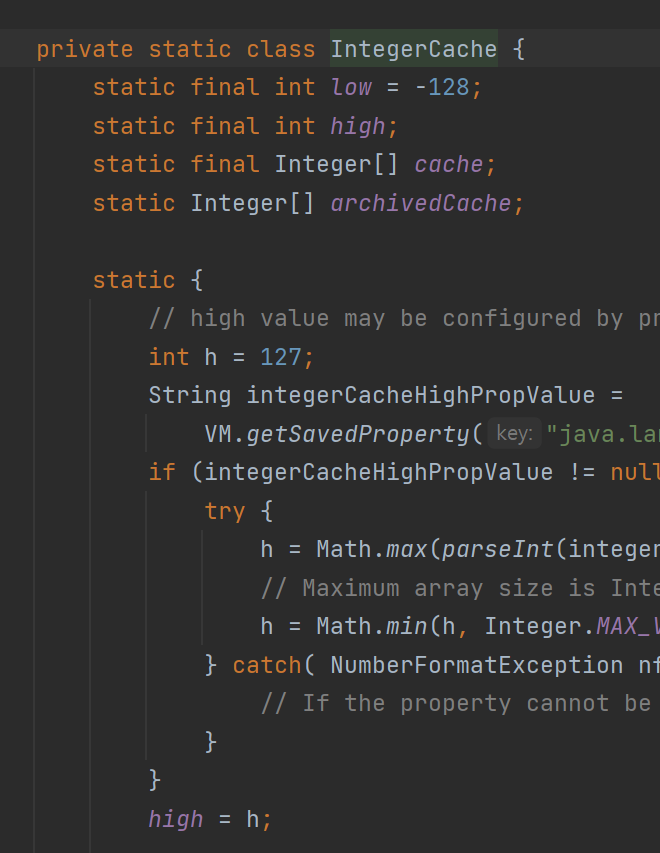
캐시 범위에 속한다면 미리 캐싱된 배열의 Integer 객체를 리턴해준다.
return IntegerCache.cache[i + (-IntegerCache.low)];
그럼 아래 디버깅을 통해서 절차를 하나씩 확인해 보자.
Integer.parseInt 디버깅
"123" 문자열을 int로 파싱 하는 과정이다.
int i = Integer.parseInt("123");
가장 처음에 parseInt가 호출돼서 내부에 오버로딩 된 parseInt로 기수와 함께 넘겨준다.

len은 "123"의 길이인 3이 되고, limit은 인티저의 MAX_VALUE의 -가 된다.
첫 번째 문자가 0보다 작으면서 '-' 였다면 아래 로직을 탔지만, 1로 시작해서 if문을 전부 무시하게 된다.
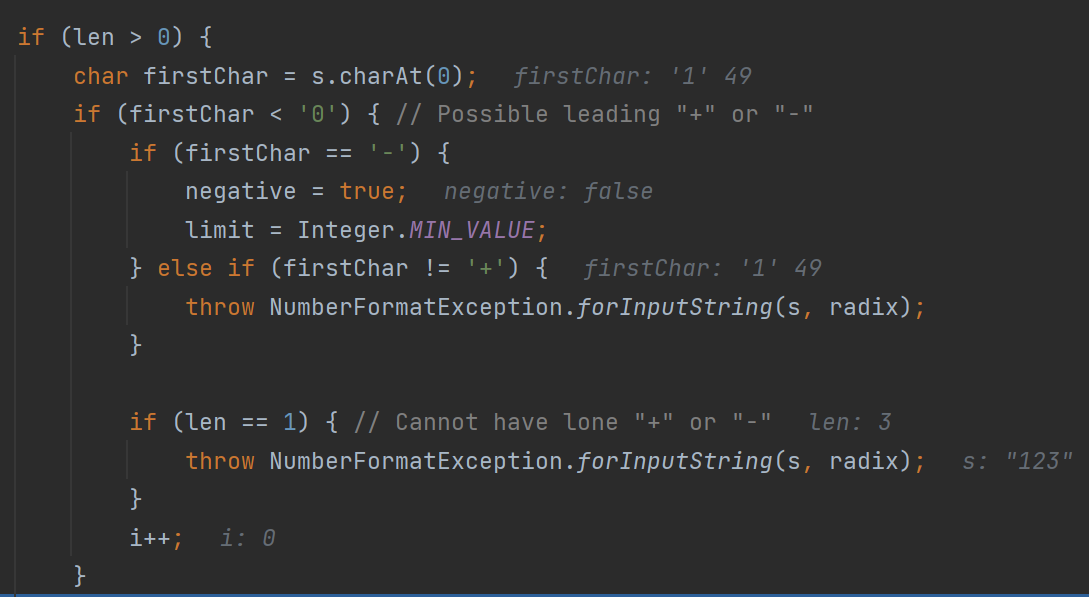
이후 while문을 통해 result를 -123으로 뽑아낸다.
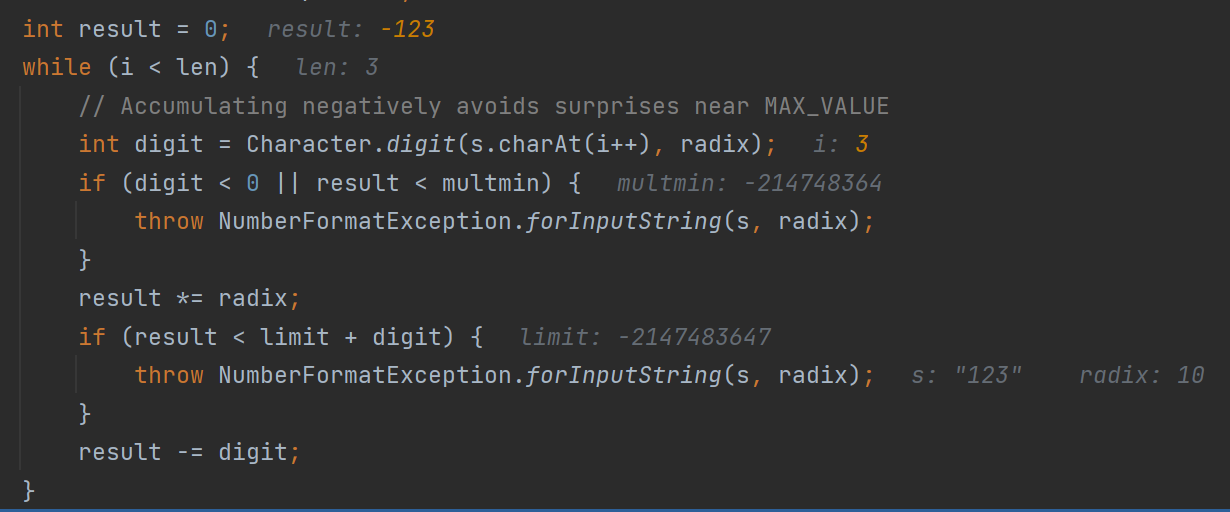
negative가 false이기에 -result를 반환해서 123이 리턴된다.

Integer.valueOf 디버깅
"123" 문자열을 int로 파싱하는 과정이다.
int i = Integer.valueOf("123");
parseInt 과정은 위에서 확인했으니 생략.

i의 값이 123으로 넘어왔고 -127 ~ 128의 범위에 해당하기 때문에 if문을 타게 된다.
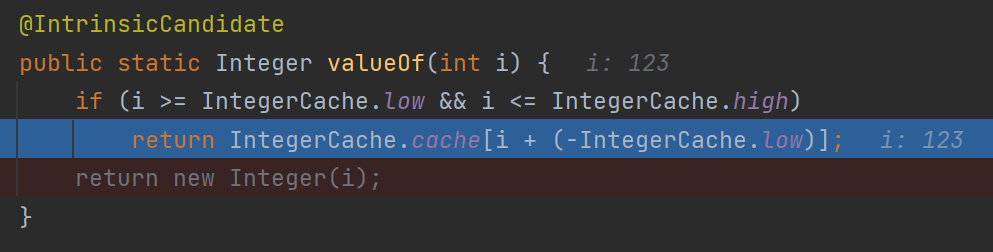
이때 IntegerCache.cache를 확인하면 256 크기의 배열로 구성되어 있으며 -128 ~ 127의 값이 이미 들어있는 상태다.
그리고 아래처럼 해당 배열의 속하면 값을 바로 리턴해준다.

여기서 궁금증이 생기는 게 있다. 애초에 처음부터 -128 ~ 127의 값을 캐싱해 놓고 해당 값이 들어오면 Integer로 리턴을 해주는데 이러면 캐싱을 해두는 의미가 있나? 싶었다.
그래서 아래와 같은 실험이 존재한다.
i1, i2는 동일한 값, i3, i4도 동일한 값을 가진다. 그러면 둘 다 true가 나와야 정상이다.
Integer i1 = Integer.valueOf("127");
Integer i2 = Integer.valueOf("127");
Integer i3 = Integer.valueOf("128");
Integer i4 = Integer.valueOf("128");
System.out.println(i1 == i2);
System.out.println(i3 == i4);
그러나 결과는 128은 다르다고 판단한다.(나도 예전에 Long에서 이런 문제를 마주쳤었다.)
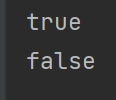
이렇게 나오는 이유가 IntegerCache 때문에 그렇다. -128 ~ 127 사이에 있다면 이미 캐싱해 둔 값을 제공한다. 그러나 그 외의 범위로 들어온다면 새로운 Integer 객체를 제공하기 때문에 두 128의 경우 다른 참조값을 가진다고 판단하는 것.
Long도 마찬가지이다. LongCache라는 것이 존재하고 얘도 -128 ~ 127의 범위를 갖는다.
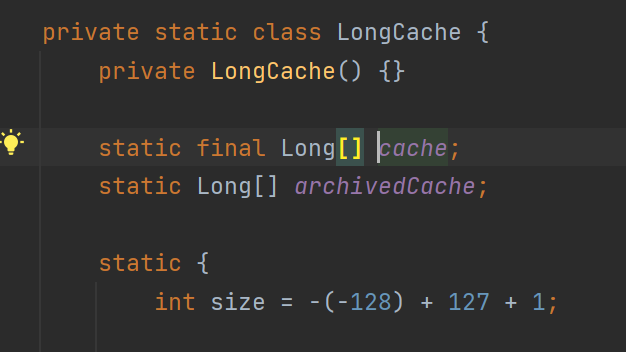
왜 -128 ~ 127의 범위를 갖는지 찾아보았지만 대부분의 대답은 "자주 사용하는 값이다."라고만 나와있다.
그러면 Integer로 받을 때 -128 ~ 127을 사용하면 미리 캐싱된 값으로 메모리를 아낄 수 있을까? 실험해 봤다.
약 100만 번 반복문을 돌고 현재 사용 중인 메모리를 출력해 봤다.
256 출력 -> 캐시 데이터를 사용하지 않는 경우
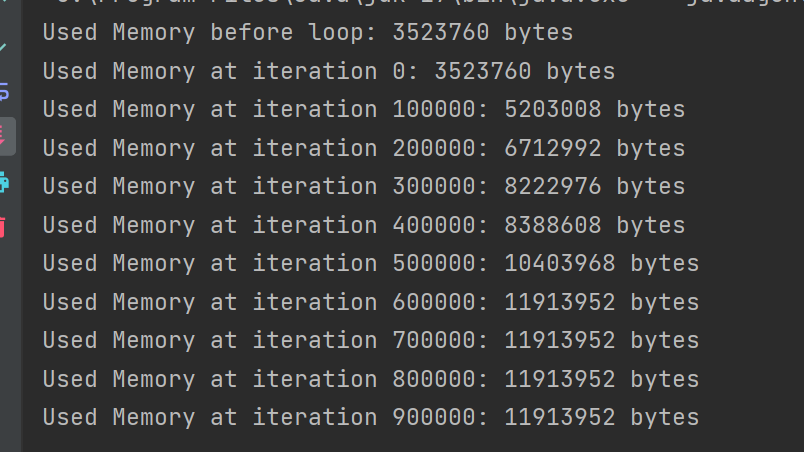
약 11.36 MB가 사용됐다.
126 출력 -> 캐시 데이터를 사용하는 경우
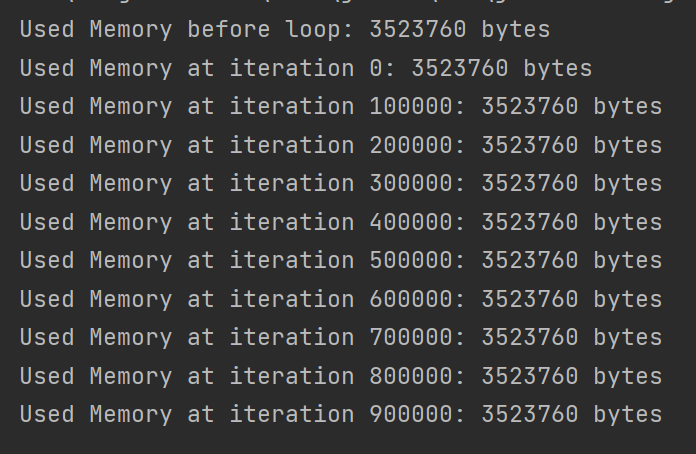
약 3.36 MB가 사용됐다.
실제 캐싱을 해놓고 객체를 제공하면 메모리 사용에 이점이 있는 것을 확인할 수 있다.
실험 코드
public static void main(String[] args) throws IOException {
BufferedReader bf = new BufferedReader(new InputStreamReader(System.in));
Runtime runtime = Runtime.getRuntime();
long usedMemoryBefore = runtime.totalMemory() - runtime.freeMemory();
System.out.println("Used Memory before loop: " + usedMemoryBefore + " bytes");
for (int i = 0; i < 1000000; i++) {
Integer i1 = Integer.valueOf("123");
// 주기적으로 메모리 사용량 출력 (예: 10,000,000번마다)
if (i % 100000 == 0) {
long usedMemoryDuring = runtime.totalMemory() - runtime.freeMemory();
System.out.println("Used Memory at iteration " + i + ": " + usedMemoryDuring + " bytes");
}
}
}'JAVA' 카테고리의 다른 글
| 개념만 알고 ArrayList 구현 해보기 (0) | 2024.11.17 |
|---|---|
| ArrayList는 어떻게 데이터를 관리할까?(디버깅 과정 포함) (0) | 2024.07.02 |
| 자바 실행 과정 및 JVM 개념 정리 (1) | 2024.03.01 |
| equals()와 hashcode() 정리(재정의) (2) | 2024.02.24 |